Abstract
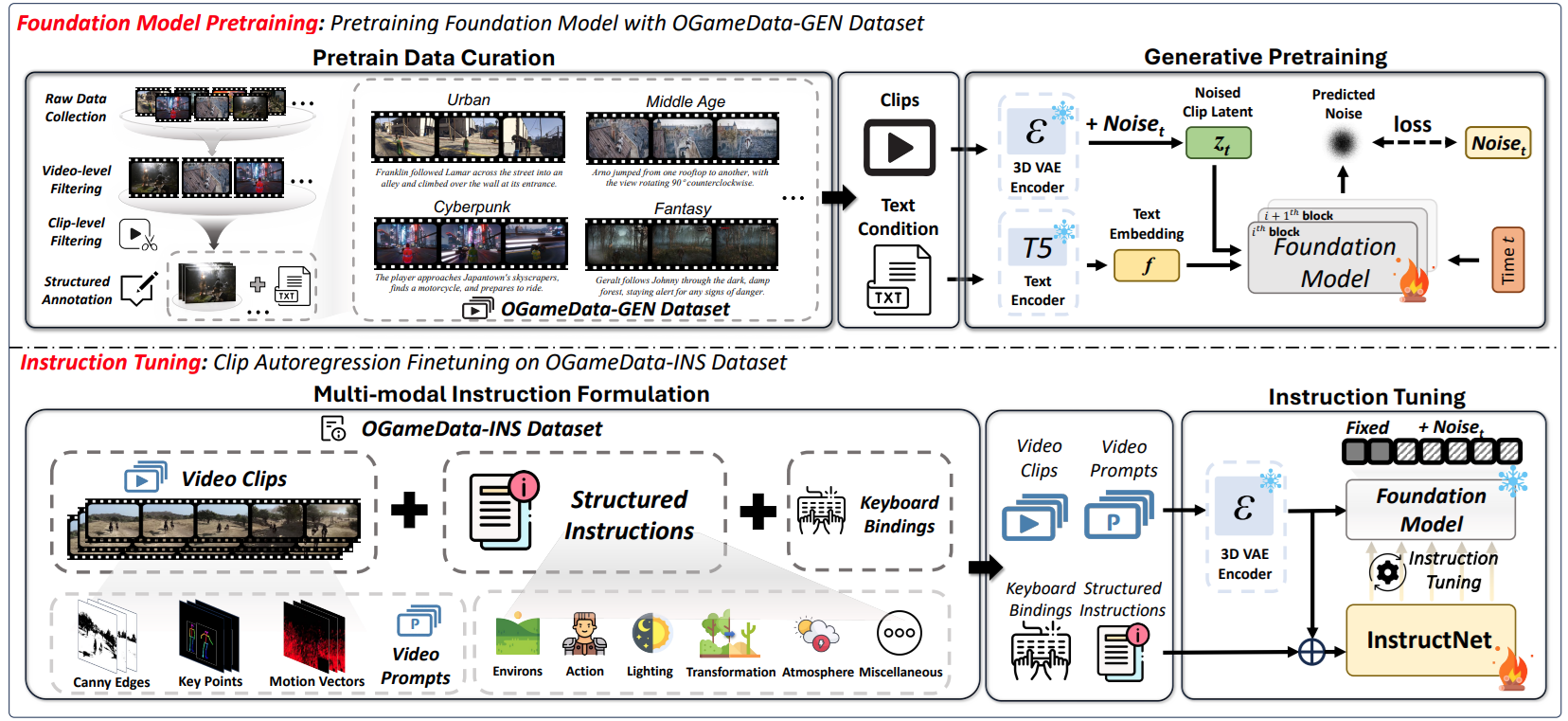
We introduce GameGen-\(\mathbb{X}\), the first diffusion transformer model specifically designed for both generating and interactively controlling open-world game videos. This model facilitates high-quality, open-domain generation by approximating various game elements, such as innovative characters, dynamic environments, complex actions, and diverse events. Additionally, it provides interactive controllability, predicting and altering future content based on the current clip, thus allowing for gameplay simulation. To realize this vision, we first collected and built an Open-World Video Game Dataset (OGameData) from scratch. It is the first and largest dataset for open-world game video generation and control, which comprises over one million diverse gameplay video clips with informative captions. GameGen-\(\mathbb{X}\) undergoes a two-stage training process, consisting of pre-training and instruction tuning. Firstly, the model was pre-trained via text-to-video generation and video continuation, enabling long-sequence open-domain game video generation with improved fidelity and coherence. Further, to achieve interactive controllability, we designed InstructNet to incorporate game-related multi-modal control signal experts. This allows the model to adjust latent representations based on user inputs, advancing the integration of character interaction and scene content control in video generation. During instruction tuning, only the InstructNet is updated while the pre-trained foundation model is frozen, enabling the integration of interactive controllability without loss of diversity and quality of generated content. GameGen-$\mathbb{X}$ contributes to advancements in open-world game design using generative models. It demonstrates the potential of generative models to serve as auxiliary tools to traditional rendering techniques, demonstrating the potential for merging creative generation with interactive capabilities. The project will be available at https://github.com/GameGen-X/GameGen-X.
For the technical detail, please refer to the original paper.
Schematic Diagram of the Proposed Method
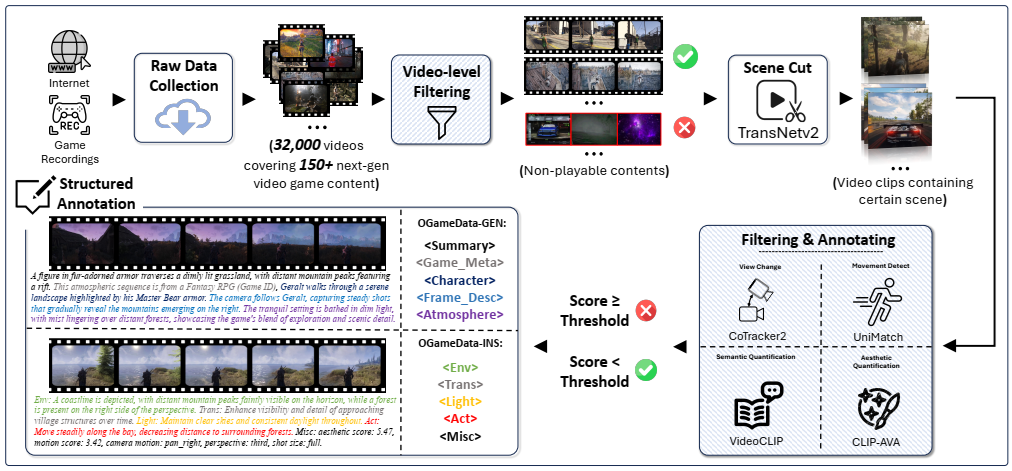
Our OGameData dataset construction process is illustrated below:
Our GameGen-\(\mathbb{X}\) model structure is illustrated below:
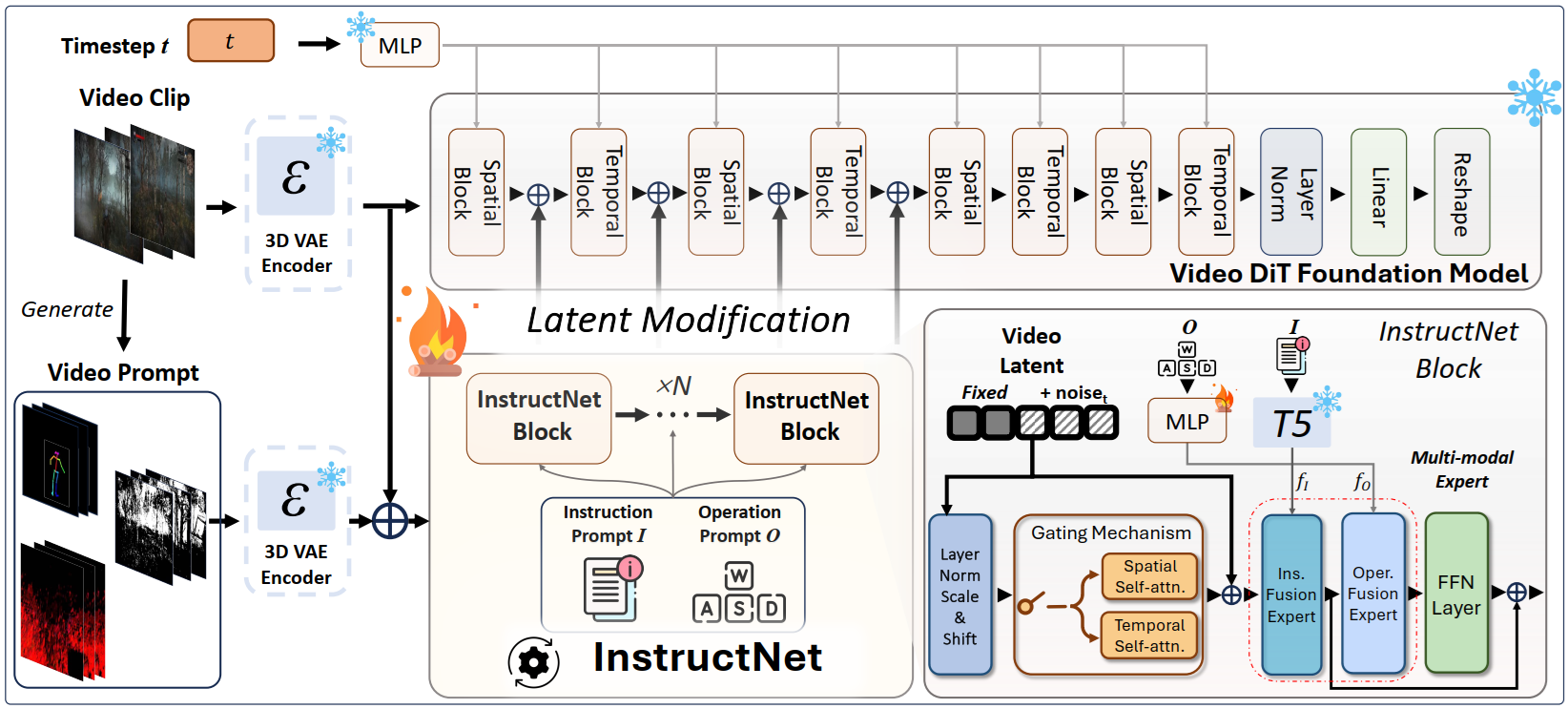
To address spatiotemporal redundancy, GameGen-X incorporates a 3D Variational Autoencoder (3D-VAE) to compress video segments into latent representations:
- Spatial Downsampling: Extracts frame-level latent features to reduce computational cost.
- Temporal Aggregation: Captures temporal dependencies, minimizing frame redundancy.
- Latent Tensor Representation: Supports long videos and high-resolution training, meeting the demands of game content generation.
GameGen-X leverages InstructNet for instruction fine-tuning, enabling user-interactive control:
- Composed of N InstructNet modules, each integrating:
- Operation-Integrated Expert Layers
- Instruction-Integrated Expert Layers
- Functionality:
- Injects instruction features to modulate latent representations, ensuring alignment with user intent.
- Supports character actions and environmental dynamics control.
- Trains via continuous video sequences to simulate game mechanics and feedback loops.
- Introduces Gaussian noise in initial frames to mitigate error accumulation.
For the technical detail, please refer to the original paper.
Downloads
Full paper: click here
PyTorch code: click here
Reference
@inproceedings{che2024gamegen,
title={GameGen-X: Interactive Open-world Game Video Generation},
author={Che, Haoxuan and He, Xuanhua and Liu, Quande and Jin, Cheng and Chen, Hao},
booktitle={International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=8VG8tpPZhe},
}